Testing Internationalization & Localization Workflows: Ensuring Accurate Multilingual Experiences
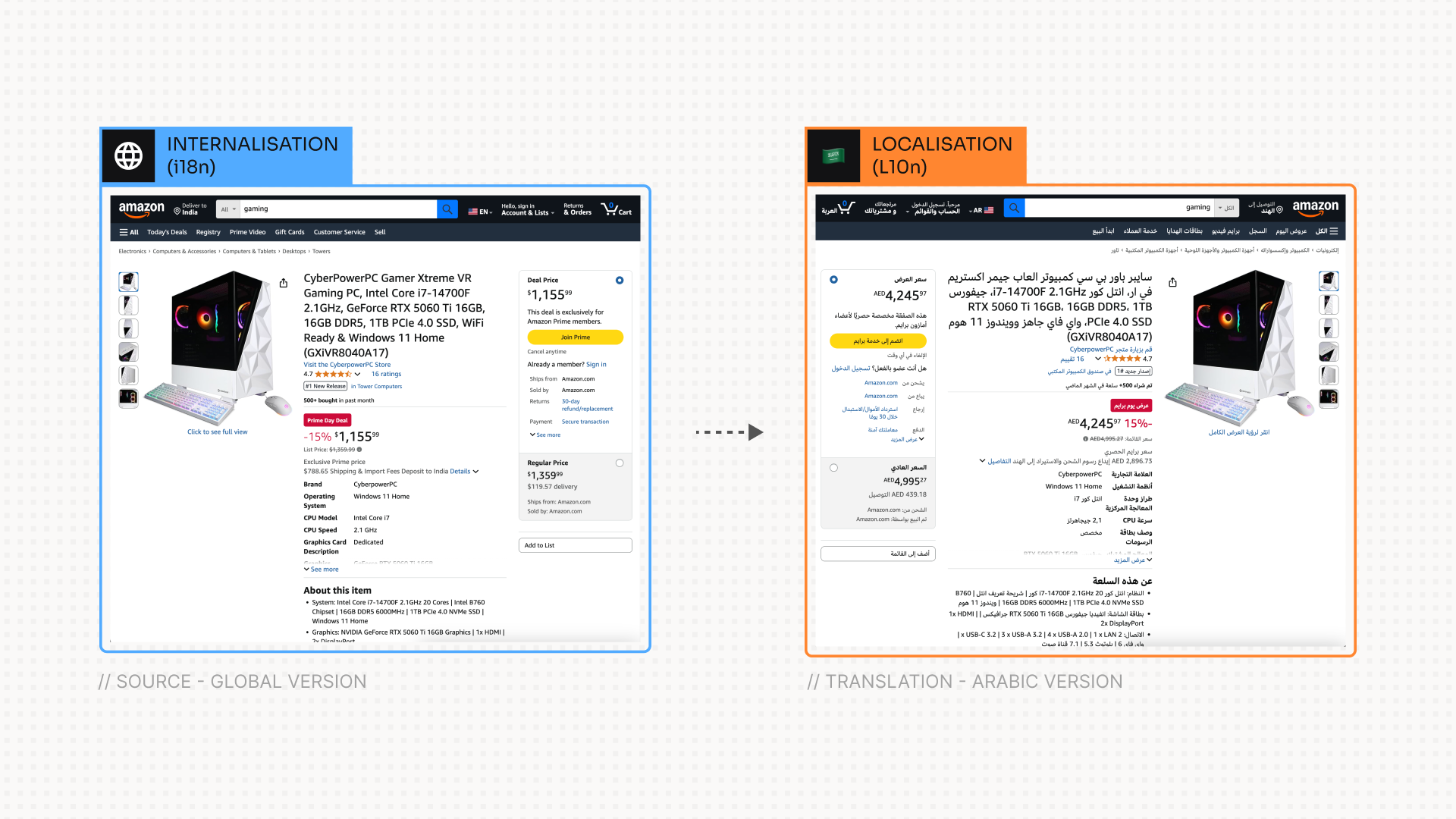
As global audiences demand seamless experiences in their native languages, robust internationalization (i18n) and localization (L10n) testing workflows have become critical to product success. This workflow harnesses automated extraction, LLM-based validation, and comprehensive reporting to compare source and localized content across two homepages. By understanding where translations may fall short—whether in coverage, cultural nuance, or linguistic precision—QA teams can proactively surface gaps, refine prompts, and deliver truly localized experiences.
Observed Challenges in i18n/L10n Testing
Coverage Gaps
- Missing or Partial Translations
- Certain UI elements (e.g., buttons, tooltips) may remain in the source language.
- Date/time formats or numbers may not adapt to target locale conventions.
- Contextual Inconsistencies
- Ambiguous text (“Save” vs. “Store”) translated literally without preserving UI intent.
- Idiomatic expressions that require paraphrasing rather than word-for-word translation.
Linguistic Precision
- Terminology Drift
- Core domain terms (e.g., “cart,” “checkout,” “shipping”) must remain consistent across pages.
- Glossaries sometimes overlooked, leading to mixed terminology.
- Grammar & Syntax
- Gendered languages may misalign articles and adjectives.
- Sentence structures that sound unnatural or reverse the intended emphasis.
Cultural & UI Nuances
- Date/Time & Numeric Formats
- MM/DD/YYYY vs. DD/MM/YYYY, thousand separators, currency symbols placement.
- Right-to-Left (RTL) Support
- Layout inversion, icon flips, and typography adjustments often skipped.
- Locale-Specific Content
- References to holidays, examples, or imagery that don’t resonate with the target audience.
Why Testers Must Master i18n/L10n Workflow Behavior
Automate with Understanding
An automated pipeline accelerates validation—but without understanding each step’s strengths and blind spots, critical errors can slip through. By inspecting how the extraction, LLM validation, and report generation handle edge cases, testers can:
- Fine-tune extraction scripts to capture dynamic content (e.g., modal text, hidden tooltips).
- Craft better prompts ensuring the LLM assesses context appropriateness, not just literal translation.
Prevent False Positives & Negatives
Blind trust in automation can produce misleading success metrics. For example:
“All strings are translated” may mask untranslated placeholders or concatenated text flows.
Knowing where the LLM may over- or under-report coverage allows QA to target manual reviews effectively.
Source vs. Localized Content Strengths
Different LLM models or translation engines exhibit unique behaviors:
- Use Model A when you need deep semantic checks (e.g., cultural nuance, sentiment alignment).
- Use Model B for broad coverage scanning (e.g., detecting untranslated segments at scale).
Selecting and version-controlling the right model ensures consistent, reproducible testing.
Key Takeaway Table
| Factor | Source Homepage | Localized Homepage |
|---|---|---|
| Content Coverage | Complete, dynamic modules included | Notices of missing UI elements |
| Terminology Consistency | Glossary-aligned | Mixed usage—requires glossary enforcement |
| Cultural Appropriateness | Neutral, global examples used | Literal translations lacking context |
| Format Adaptation | Native date/time/number formatting | Partial—some formats still in source style |
| Automation Readiness | HTML extraction scripts robust | Requires manual overrides in scripts |
Actionable Guidance for Localization QA Engineers
Version Control Your Workflow Components
- Tag extraction scripts, LLM prompt templates, and report generators.
- Maintain changelogs for prompt modifications and model versions.
Compare Multiple Models/Engines
- Run translations through two different LLM validators or engines.
- Highlight discrepancies side by side in your HTML report.
Augment Prompts with Contextual Cues
- Include UI location, character limits, and tone guidelines in prompts.
- Use examples of ideal translations from your glossary.
Establish Manual Checkpoints
- For high-impact sections (pricing tables, legal text), assign human reviewers.
- Use report annotations to draw attention to flagged segments.
Teach Teams to “Think Like the LLM”
- Share common LLM failure modes (e.g., misplacing gendered terms, skipping concatenated text).
- Run periodic training sessions to build prompt literacy.
Final Words: The Future of Localized Quality Assurance
Localization is no longer a last-minute checkbox—it’s a core product capability that drives user trust and engagement worldwide. By integrating automated extraction, LLM-driven validation, and structured reporting, testers empower teams to uncover hidden gaps and refine localization strategies continuously. Embrace the full i18n/L10n testing workflow, version every component, and foster a culture of prompt literacy. The result? Truly global products that speak your users’ language—literally and culturally.